หลังจากที่ผมได้อธิบายข้อมูลเชิงลึกของชิพ D1 ไปในกระทู้ [เจาะลึก]Tesla เปิดตัว D1 ชิพ(5 หมื่นล้านทรานซิสเตอร์) สร้างมาเพื่อใช้ฝึก AI โดยเฉพาะ มาในกระทู้นี้ผมจะขออธิบายแผง Training tile ซึ่งรวมตัวชิพ D1 มากถึง 25 ตัวให้กลายเป็นแผงวงจร Super Computer ที่มีพละกำลังมากถึง 9 Petaflops เทียบเท่า 9,216 Teraflops หรือเทียบเท่ากับการประมวลผลของการ์ดจอ RTX 3090 มากถึง 250 ใบครับ
ก่อนจะเข้าไปดูข้อมูลของเจ้า Training tile ผมขอทบทวนข้อมูลเกี่ยวกับชิพ D1 หน่อยนะครับ ชิพ D1 นั้นมีขนาดเล็กกว่าฝ่ามือคนแต่ปรากฏว่าสามารถประมวลผลได้สูงถึง 362 TFLOPs กันเลยทีเดียว แถม Bandwidth ในการรับส่งข้อมูลภายในชิพนั้นสูงถึง 10 tbps(ต่อ direction)และการส่งข้อมูลสู่ภายในนั้นสามารถทำได้สูงสุดที่ 16 tbps หรือมากกว่า network chipset ในปัจจุบันถึง 2 เท่า

เอาล่ะครับ หลังจากที่ทุกคนได้อ่านข้อสรุปจากโพสที่แล้วกันมาบ้างแล้วถึงเวลาที่ Training Tile จะได้ออกโรงกันแล้วนะครับ
ก่อนอื่นเลยผมขอย้อนกลับไปที่สเปคเครื่อง Super Computer ของ Tesla ที่ใช้อยู่ในปัจจุบันก่อนนะครับ เครื่อง Supercomputer นี้เป็นสุดยอดคอมพิวเตอร์ที่มีความแรงเป็นอันดับ 5 ของโลกครับ
เอาละครับเรามาดูสเปคซุปเปอร์คอมพิวเตอร์เครื่องนี้กันเถอะครับ
- 8x A100 80GB x 720 เครื่อง (มีการ์ดจอ(GPU)จำนวน 5760 ใบ)
- 1.8 EFLOPS (720 nodes * 312 TFLOPS-FP16-A100 * 8 gpu / nodes)
- 10 PB of “hot tier” NVME storage @ 1.6 TBps
- 640 Tbps of total switching capacity

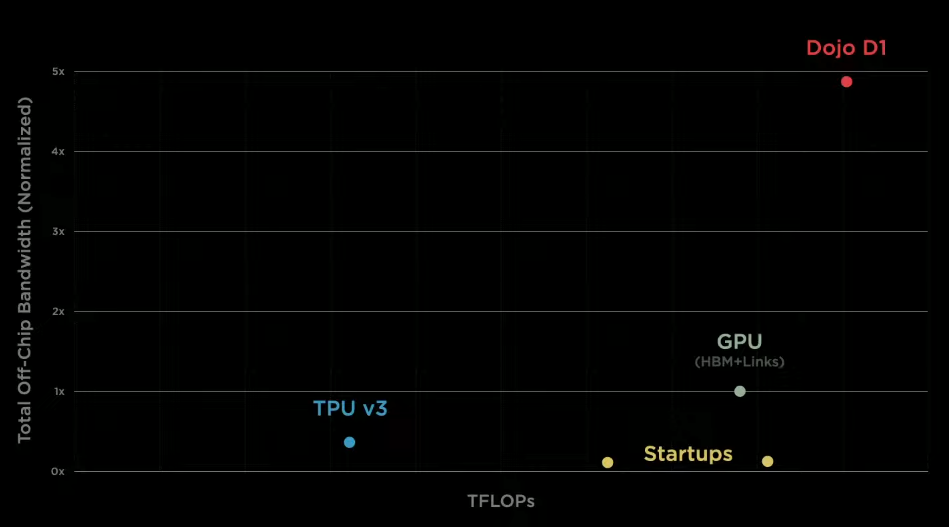
Chipset Nvidia A100 นั้นเป็นชิพที่แรงและเร็วที่สุดของค่าย nvidia แล้วนะครับ A100 จำนวน 1 ตัวนั้นสามารถประมวลผลได้เร็วถึง 312 Teraflops ซึ่งช้ากว่าชิพ D1 ของ Tesla ประมาณ 50 Teraflops อยู่ดีครับ
อย่างไรก็ตาม เวลา nvidia ทำ supercomputer นั้นจะสามารถเอาชิพ A100 มาใส่ในแผง mainboard ได้เพียง 8 ตัวเท่านั้น ในขณะที่ Tesla ได้ออกแบบแผ่น training tile ที่สามารถใส่ชิพ D1 ได้ถึง 25 ตัว (ต่างจากรุ่นนี้ถึง 3 เท่า)

สำหรับใครที่ยังไม่ได้ดูการเปิดตัว Tesla Supercomputer และการเปิดตัว Server ด้านบนนี้ก็สามารถรับชม live ย้อนหลังที่ผมได้กลั่นกรองข้อมูลของคุณอัลเดรมาเป็นภาษาไทยที่คลิปด้านล่างนี้นะครับ
ชิพ D1 คืออะไร?
“There is no dark silicon, no legacy support, this is a pure machine learning machine. This was entirely designed by Tesla team internally, all the way from the architecture to the package. This chip is like GPU-level compute with a CPU level flexibility and twice the network chip-level I/O bandwidth.”
ชิพตัวนี้ไม่มี dark silicon(useless silicon คือซิลิคอนในชิพที่เป็นของเสียในชิพ – อ่านต่อเพิ่มเติมด้านล่าง), ไม่ใช้ legacy support เพราะชิพตัวนี้ออกแบบมาให้รัน software สำหรับ machine learning เท่านั้น ซึ่งทีมพัฒนาของเทสล่านั้นได้ออกแบบชิพตัวนี้ใหม่หมดจดกันเลยทีเดียว ชิพตัวนี้จะสามารถประมวลผลได้แบบ GPU (การ์ดจอ)พร้อมกับทำงานสลับซับซ้อนได้ดีแบบ CPU และสามารถรับส่งข้อมูล(I/O Bandwidth)ได้ดีกว่า network chip ถึง 2 เท่า
คุณกาเนซ (ผู้บริหารระดับสูงในโปรเจค Autopilot) ได้กล่าวเอาไว้ในงาน AI Day
หรือจะพูดได้ว่าชิพของเทสล่าในปัจจุบันนั้นเต็มไปด้วยความแรง(แรงกว่า)การ์ดจอขั้นเทพ(Nvidia A100)ในท้องตลาดไปแล้ว แถมการประมวลคำสั่งต่างๆของชิพนั้นก็แฝงความสามารถ CPU คอมพิวเตอร์ไปด้วย สิ่งที่คุณกาเนซเน้นย้ำคือการรับส่งข้อมูล(I/O Bandwidth) ที่สามารถทำได้ดีกว่า Network chipset ที่วางขายในท้องตลาดไปเสียแล้วครับ
Dark silicon นี่เป็น useless silicon(ไร้ประโยชน์)ที่อยู่ในชิพและเป็นส่วนที่กินไฟมากที่สุดในพื้นที่ของชิพครับ ซึ่งปกติแล้วถ้าระบบไม่อยากเปลืองไฟเยอะก็จะเลี่ยงการจ่ายไฟไปยังพื้นที่นั้น และการมี dark silicon ในชิพก็ทำให้ชิพตัวนั้นเสียพื้นที่และประโยชน์ในการใช้งานลงไปอย่างมากครับ
ปล. บทความเรื่อง Dark Silicon ยังไม่มีใครแปลเป็นภาษาไทยนะครับ ทำให้ผมต้องไปอ่านจาก Research ย้ำว่า Research เลยครับ เว็บธรรมดาๆ ของฝรั่งไม่เขียนความหมายทิ้งเอาไว้ให้อ่านกันเลย ถ้าผมแปลผิดไปตรงนี้(รบกวนผู้รู้แจ้งมาได้ที่ Blink Drive นะครับ) ผมจะทำการแก้ไขข้อมูลให้ถูกต้องครับ
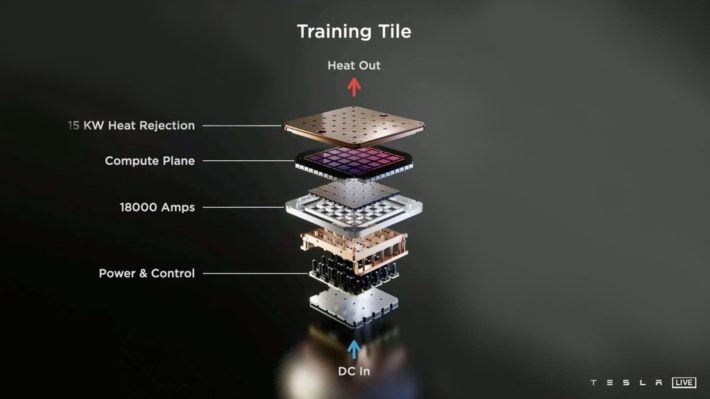
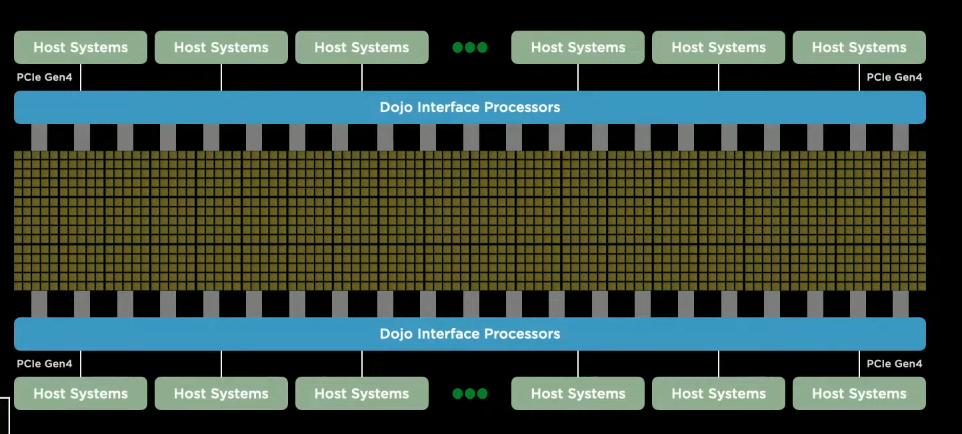
สเปค Training tile
อย่างทีผมกล่าวไปด้านบนคือ nvidia ทำ supercomputer นั้นจะสามารถเอาชิพ A100 มาใส่ในแผง mainboard ได้เพียง 8 ตัวเท่านั้น ในขณะที่ Tesla ได้ออกแบบแผ่น training tile ที่สามารถใส่ชิพ D1 ได้ถึง 25 ตัว (ต่างจากรุ่นท๊อปของ Nvidia ถึง 3 เท่า)

สังเกตุดีๆ ว่าการสร้าง training tile นั้นจะเป็นแบบ 5 x 5 ซึ่งเท่ากับว่าใช้ชิพ D1 ทั้งหมด 25 ตัวโดยชิพเหล่านี้จะสามารถส่งข้อมูลไปมาหากันด้วยความเร็ว Bandwidth ที่ 4 TB/s ต่อด้าน(รวม 4 ด้านแล้ว ชิพตัวนึงจะสามารถรับส่งข้อมูลได้มากถึง 16 TB/s)
หมายเหตุ : TB/s คือ Terabytes ต่อวินาที
แต่ถึงอย่างไรก็ตามนี่คือความเร็วในการรับส่งข้อมูลระหว่างชิพ D1 ในแผงของ Training Tile นะครับ ถ้าจะส่งข้อมูลออกจากแผง Training Tile แล้วจะสามารถรับ-ส่งข้อมูล(I/O Bandwidth) อยู่ที่ 9 TB/s ต่อด้านนะครับ รวม 4 ด้านเข้าไปก็ประมาณ 36 TB/s ครับ

ถ้าถามว่า 36 TB/s นี่เยอะแค่ไหน ลองกลับไปดูตู้ server ของ Nvidia A100 ที่มี A100 อยู่ 8 ตัวแล้วก็มี Network Card อยู่ 8 ตัวนะครับ เค้าสามารถรับส่งข้อมูลสูงสุดที่ 500 GB/s Bi-direction(สองทิศทาง)ซึ่งแปลว่าสามารถทำได้สูงสุดที่ 1 TB/s หรือน้อยกว่า Training Tile ของ Tesla ถึง 36 เท่าครับ
9 PFLOPS !? แม่เจ้า แรงแค่ไหนมาดูกัน
ส่วนเรื่องการประมวลผลนั้น Training Tile ตัวนี้สามารถประมวลผลได้ที่ 9 PFLOPS BF16/CFP8 เทียบเท่าการประมวลผลของ RTX 3090 ซึ่งเป็นการ์ดจอเทพระดับ end user บนโลกนี้ตอนนี้(2021)นั้นประมาณ 256 ใบครับ
ส่วนการประมวลผลแบบ Single-precision floating-point format หรือที่เรียกว่า FP32 นั้นทำได้อยู่ที่ 565 TFLOPS เทียบเท่าการประมวลผลของ PS5 ประมาณ 55 เครื่องพร้อมๆ กันครับ
Training Tile ใหญ่แค่ไหน?
เอาล่ะครับ ทุกท่านเริ่มอยากเห็นหน้าตาไอ่เจ้า Training Tile กันแล้วสินะครับว่าหน้าตาเป็นอย่างไร มาดูกันเลยตรงนี้ครับ

นี่คือ Training Tile ที่มีความแรงระดับ 9 PFLOPS หรือเทียบเท่าการ์ดจอ RTX 3090 ถึง 256 ใบจะมีขนาดประมาณกระดานหมากรุกและสามารถถือได้แบบชิว ๆ แบบนี้ครับ
จ่ายไฟเข้ายังไง?
คุณกาเนซก็บอกว่า ก็จ่ายตรงๆ ลงไปด้านบนของชิพทุกตัวนี่แหละครับ อุปกรณ์หลากหลายตัวตรงการแผง Training tile นั้นคือระบบ Power Supply ของชิฟแต่ล่ะครับ

การจ่ายไฟนั้นจะทำกันแบบละเอียดและซับซ้อนมากๆ ดังนั้นปัญหาที่ตามมาคือเรื่องความร้อนครับ ทำให้เค้าต้องออกแบบระบบระบายความร้อนแบบ liquid cooling กันเลยทีเดียวซึ่งใช้ทองแดงเป็นหลักในการทำ case ของ training tile ครับ

ส่วนภาพนี้คือภาพด้านหลังของตัว Training Tile ซึ่งจะถูกแปะด้วย Heat Sink(แผงระบายความร้อน)อีกชั้นเข้าไปครับ

นี่คือหน้าตา layout ของ Training Tile ในแต่ล่ะชั้นครับ ซึ่งเท่าที่ดูคือ ไฟฟ้าจะเข้าจากด้านล่างและพอชิพประมวลผลทั้งหมดก็จะคายความร้อนออกทางด้านบนครับ

อย่างไรก็ตามนี่คือหน้าตาของเครื่อง Training Tile ที่ใช้งานจริงๆครับ

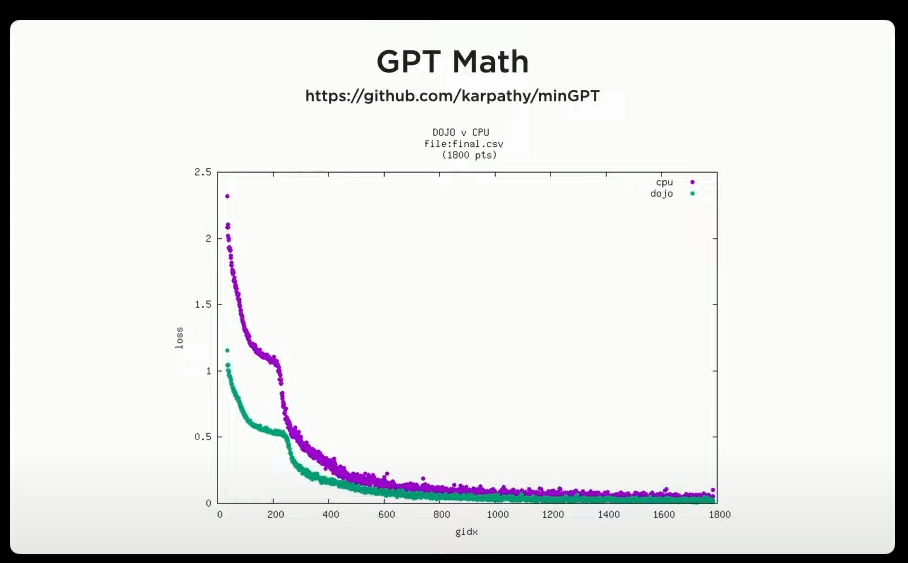
และที่สำคัญคือเครื่องนี้สามารถประมวลผลได้ดีกว่า CPU ที่คุณอันเดร์ใช้งานในปัจจุบันด้วย ซึ่งตอนที่ slide นี้โผล่ขึ้นมา คุณกาเนซหันไปมองคุณอัลเดร์แล้วพูดว่า
Andrej, this is minGPT running on dojo. Do you believe it?
อันเดร์ ผมเอา minGPT มารันบนเครื่อง dojo ที่ผมสร้างขึ้นมา มันน่าทึ่งใช่ไหม?
คุณกาเนซ (ผู้บริหารระดับสูงในโปรเจค Autopilot) หันไปพูดกับคุณอัลเดร(ผู้บริหารระดับสูงด้าน AI และ Autopilot Vision)
ที่มา : datacenterdynamic
BLINK DRIVE TAKE
เดี๋ยวพรุ่งนี้(ถ้าผมมีเวลา)จะมาเขียนต่อเรื่อง Training Mat นะครับ นี่คือการเอา Training Tile หลายๆ ตัวมาเรียงต่อกันเป็นแบบพรม(ด้านล่างนี้)

จากนั้นก็ทำการปล่อยให้ Training Tile แต่ละตัวส่งข้อมูลไปมาหากันซึ่งการทำแบบนี้จะสามารถลดเส้นทางและระยะเวลาการเดินทางของข้อมูลได้อย่างมหาศาลเลย แต่ก่อนนั้นการเชื่อมต่อจะเป็นแบบ Hub to Hub หรือจะเป็นการเชื่อมต่อแบบ Bus line แต่ก็เชื่อมต่อแบบนี้(Peer to Peer) จะทำให้ Chip แต่ล่ะตัวทำงานกันอย่างอิสระมากยิ่งขึ้นและประมวลผลได้มีประสิทธิภาพมากขึ้นอย่างมหาศาลเลยนะครับ

ถ้าทุกท่านชอบผลงานนี้ก็อย่าลืมกด like กันในโพสหลักหน้า Facebook Fanpage ของ Blink Drive นะครับ เพื่อให้ผมรับทราบว่ายังมีคนอยากอ่านอยู่ครับ ฮ่าๆ