ยังไงแล้ว ผมต้องขอทำการย้อนเวลากลับไปเมื่อ 2 เดือนที่แล้วที่ คุณอันเดร์ (Andrej Karpathy) หัวหน้าวิจัยแผนก AI (Artificial Intelligence)หรือปัญญาประดิษฐ์ ของเทสล่าได้ออกมาพูดเกี่ยวกับหัวข้อ Tesla Dojo เป็น supercomputer ที่แรงเป็นอันดับ 5 ของโลกในวันนั้นนะครับ ซึ่งตอนนั้น Dojo ของ Tesla ใช้การ์ดจอ 5,760 ใบจาก nvidia ในการประมวลผล โดยตอนนั้นเทสล่าใช้คอมพิวเตอร์ในการประมวลผลดังนี้ครับ
สเปค Tesla Super Computer (ตอนใช้ชิฟของ Nvidia
ก่อนอื่นเลย สเปคเครื่องซูปเปอร์คอมพิวเตอร์ของเทสล่าเครื่องนี้เป็นเซิร์ฟเวอร์ที่ใหญ่และแรงเป็นอันดับ 5 ของโลกเลยนะครับ เครื่องนี้เป็นเครื่องก่อนที่เทสล่าจะเปลี่ยนมาใช้ D1 Chip นะครับ
เอาละครับเรามาดูสเปคซุปเปอร์คอมพิวเตอร์เครื่องนี้กันเถอะครับ
- 8x A100 80GB x 720 เครื่อง (มีการ์ดจอ(GPU)จำนวน 5760 ใบ)
- 1.8 EFLOPS (720 nodes * 312 TFLOPS-FP16-A100 * 8 gpu / nodes)
- 10 PB of “hot tier” NVME storage @ 1.6 TBps
- 640 Tbps of total switching capacity


สำหรับใครที่ยังไม่ได้ดูการเปิดตัว Tesla Supercomputer และการเปิดตัว Server ด้านบนนี้ก็สามารถรับชม live ย้อนหลังที่ผมได้กลั่นกรองข้อมูลของคุณอัลเดรมาเป็นภาษาไทยที่คลิปด้านล่างนี้นะครับ
อย่างไรก็ตาม ผมขอเอาความหมายของคำว่าโดโจที่เทสล่าพูดบ่อยๆในคลิปมาอธิบายให้ทุกคนเข้าใจกันก่อนที่เจาะลึกเข้าไปในสเปคของ Tesla D1 Chip นะครับ
どうじょうอ่านว่า โดโจ แปลว่าอะไรกันน้า?
หมายเหตุ : dojo (อ่านว่า โดโจ) นั้นเป็นคำศัพท์มาจากภาษาญี่ปุ่น โดยคำว่า “โด” มีความหมายถึงวิธีหรือแนวทาง ส่วน “โจ” มีความหมายถึงห้องโถงหรือสถานที่ขนาดใหญ่
แปลรวมๆ กันเป็น สถานที่ ๆ ใช่ฝึกวิถีทางต่าง ๆ ซึ่งถ้าพูดคำว่า โดโจในประเทศญีปุ่นนั้น คนทั่วไปจะตีความว่าเป็นสำนักฝึกดาบ(ไม้), คาราเต้, หรือศิลปะป้องกันตัวต่างๆ นะครับ

แต่ถ้าจะแปลในความหมายที่ Tesla นำมาใช้ก็คือสถานที่ฝึกวิถีทางการเรียนรู้เส้นทางและ object (วัตถุ)ต่างๆ บนท้องถนนให้กับ AI นั่นไงล่ะครับ อย่างไรก็ตามบทความนี้จะขอเจาะลึกไปทางเรื่อง Hardware ที่นำมาใช้งานการฝึก AI ของ Tesla นะครับ ส่วนบทความถัดๆ ไปจะเจาะลึกเรื่อง software และวิธีการฝึก Tesla AI ครับ
จริงๆ แล้วเทสล่าก็ใช้ Supercomputer ที่มีความแรงเป็นอันดับ 5 ของโลกไปแล้วนะครับ แต่พวกเค้าพบว่า…..
สเปค computer ที่ใช้ต่ำเกินไป?
Milan Kovac ได้ออกมาพูดในวัน Tesla AI Day ว่า
We’ve been scaling our neural network training compute dramatically over the last few years, Today, we’re barely shy of ten thousand GPUs. … But that’s not enough.”
แปล เราพยายามขยายขอบเขตการพัฒนา neural network (โครงข่ายประสาทเทียม)ในการฝึก computer ของเราให้ฉลาดยิ่งขึ้นในหลายปีที่ผ่านมา แม้กระทั่งวันนี้ เรามีการ์ดจอระดับโลกอยู่ในมือมากกว่า 10,000 ใบแต่ก็ไม่เพียงพอต่อการใช้ประมวลผลข้อมูลเหล่านั้น
Milan Kovac หัวหน้าวิศวกรแผนก Autopilot
นั่นก็เป็นที่มาที่ทำให้ Tesla ต้องหันมาผลิต Chipset เองเพื่อลดต้นทุนและสร้างชิฟที่มีประสิทธิภาพในการประมวลผลเฉพาะทางของ AI ที่เทสล่านำใช้ยังไงล่ะครับ เอาล่ะครับ เรามาดูสเปคของ D1 Chip อันนี้กันดีกว่าครับ
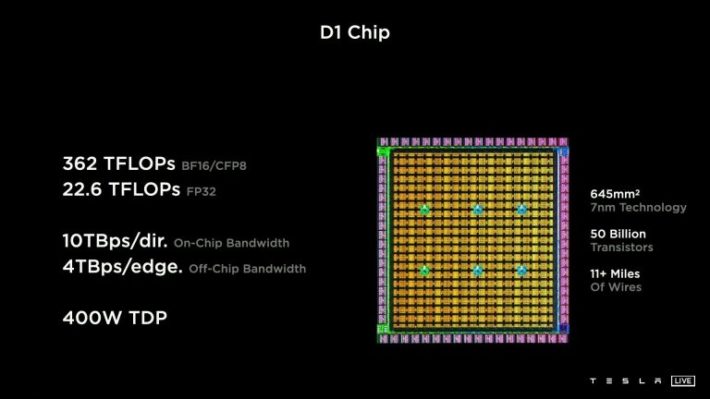
สเปค D1 Chip
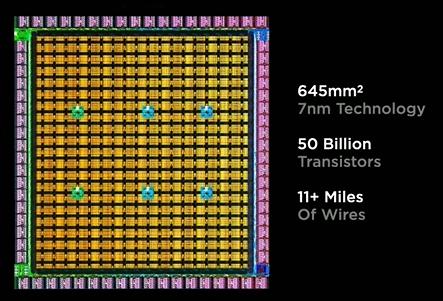
เทคโนโลยี 7 nm
เอาง่ายๆ ว่า ชิฟระดับเทพอย่าง intel Core i9 นั้นยังใช้เทคโนโลยี 14 nm(ตัวเลขยิ่งน้อยยิ่งประสิทธิภาพสูงขึ้น) ณ ปัจจุบันนั้นค่ายที่ทำ ชิฟเล็กกว่า 7 nm นั้นมีเพียงไม่กี่ค่ายบนโลกแต่ถ้าพูดชื่อทุกท่านคงร้องอ๋อทันทีซึ่งนั่นก็คือ Apple M1 Chipset ที่ใช้ชิฟขนาด 5 nm นะครับ
การที่ Tesla หันมาผลิตชิฟ 7nmเองแบบนี้ทำให้เค้าสามารถใส่ทรานซิเตอร์ได้มากขึ้นถึง 5 หมื่นล้านตัวและสามารถเพิ่มประสิทธิภาพของชิฟได้มากกว่าการสั่งซื้อจากผู้ผลิตที่ไม่ได้ผลิตชิฟตามความต้องการของเทสล่า
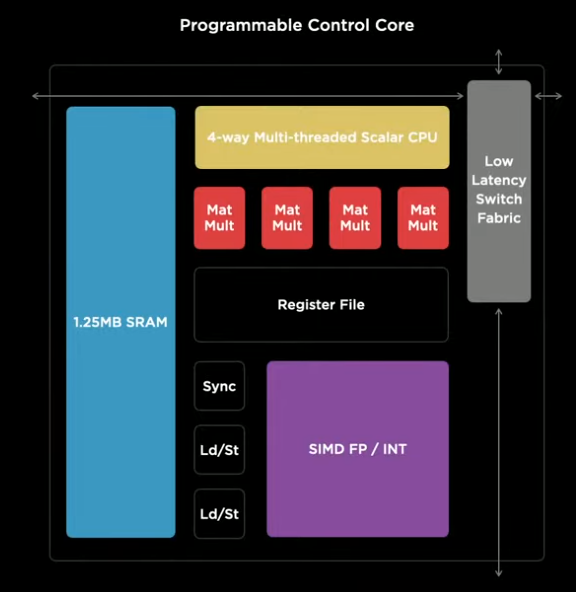
Training Node ประสิทธิภาพสูง
ภาพด้านข้างนี้คือหน้าตาของ 1 training nodes ซึ่ง Tesla ได้ทำการออกแบบเองทั้งหมดทั้งหมดสามารถยัด hardware ที่เทสล่าต้องการใช้งานเป็นหลักได้ เช่น
- SIMD(Single-instruction multiple-data-stream) รองรับ FP32, BFP16 , และ CFP8
- 1.25 MB High-Speed ECC Protected SRAM(static RAM)
- Low Latency Switch Fabric(ตัวสื่อสารระหว่าง Node)
หมายเหตุ : SRAM (static RAM) เป็นหน่วยความจำชั่วคราวที่รักษาบิตข้อมูลในหน่วยความจำ ตราบที่ยังมีพลังงานจ่ายให้ ซึ่งแตกต่างจาก dynamic RAM (DRAM) ที่เก็บบิตในเซลล์ที่ประกอบด้วยคาปาซิเตอร์ และตัวต้านทาน SRAM จะไม่มีการ refresh เป็นระยะ ๆ SRAM ให้การเข้าเก็บข้อมูลเร็วกว่าและแพงกว่า DRAM และ SRAM จะใช้เป็น cache memory ของคอมพิวเตอร์ และเป็นส่วนของ random access memory digital-to-analog converter (RAMDAC) บนการ์ดวิดีโอ – ที่มา : art

เสปค Training Nodes
- BF16/CFP8 = 1 Teraflops
- FP32 = 64 Gigaflops
- การส่งข้อมูล : 512 GB ต่อวินาที
D1 Chip 1 ตัวมี 354 Training Nodes

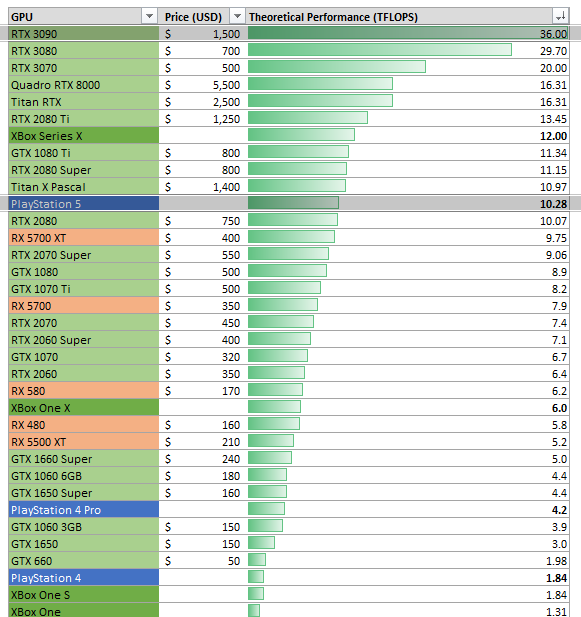
อันนี้เป็น Highlight เลยนะครับว่า Training Node ที่ทุกท่านเห็นด้านบนนั้นเป็นส่วนเล็กๆ ส่วนนึงใน D1 Chip ครับผมซึ่ง Training Nodes เหล่านี้จะประกอบกันเป็น D1 Chipset ที่บรรจุ Training Modes เข้าไปถึง 354 ตัวทำให้ชิฟ D1 มีความแรงมากถึง 362 TFlops ซึ่งเทียบเท่าความแรงระดับการ์ดจอ RTX 3090 (35.58 TFlops) ประมาณ 10 ใบครับ
ส่วนความแรงแบบ Single-precision floating-point format หรือที่เรียกว่า FP32 นั้นชิพ D1 จะทำได้ที่ 22.6 TFlops ซึ่งแรงกว่า PS5 อยู่ประมาณ 2 เท่าตัวครับ จริง ๆแล้วเท่าที่ดูคือชิพ D1 ของ Tesla ต้องการฮาร์ดแวร์ที่ใช้คำนวนแบบ BF16 มากกว่าจึงเน้นที่ส่วนนี้ทำให้สามารถทำความแรงได้ถึง 362 Tflops จาก BF16/CFP8 ครับ

Bisection BW
ชิฟ D1 นั้นสามารถส่ง-รับข้อมูลพร้อมๆ กันได้ถึง 10 TB/s ต่อ 1 direction ซึ่งแปลว่าสามารถ send และ receive พร้อมๆ กันได้อย่างล่ะ 10 TB/s ครับ
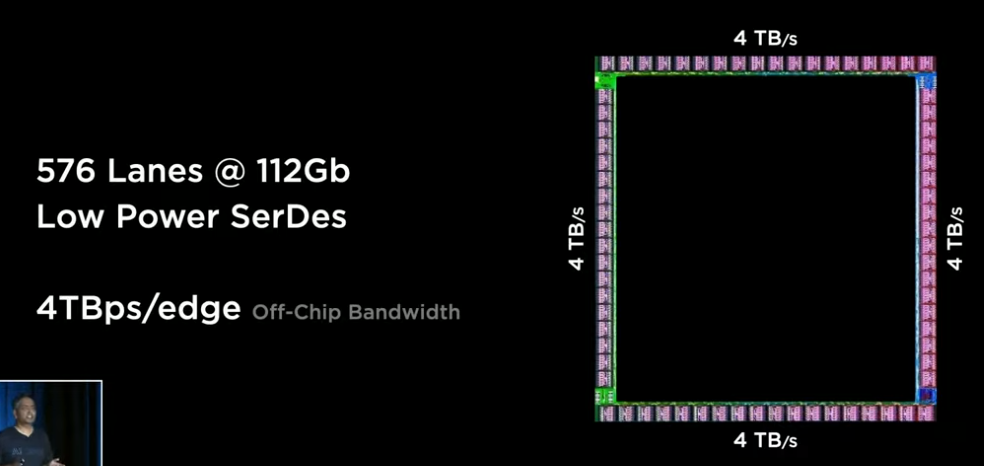
I/O Ring
สร้างช่องทางการส่งข้อมูลได้มากถึง 576 เลนและทุกๆ ด้านของชิฟตัวนี้สามารถปล่อย Bandwidth ได้มากถึง 4 TBps/ด้าน นั่นหมายความว่า ชิฟ D1 ตัวนี้รับส่งข้อมูลได้เยอะกว่า Intel® Core™ i9-11900KB Processor (ที่สามารถรับ-ส่งข้อมูลที่ 51.2 GBs) อยู่ประมาณ 312 เท่าเองครับ
คุณกาเนซได้ออกมาบอกว่านี่เป็นชิฟที่สามารถรับส่ง bandwidth ได้มากกว่า networking switch chip (พวก Cisco switch) ถึง 2 เท่าครับ
หมายเหตุ : พวก networking switch ก็คือพวก switch ที่มีหน้าตาแบบนี้และรับสาย lan เป็นจำนวนมากต่อเข้ามาในเครื่องครับ ซึ่งส่วนใหญ่ตอนนี้ Chip ที่ทำความเร็วที่สุด(เท่าที่ผมทราบมานะครับ)คือ Barefoot Tofino 2 ซึ่งทำได้ที่ 12.8 Tbps ซึ่งยังช้ากว่าชิฟ D1 ของเทสล่าอยู่ดีครับ

แล้วชิฟ D1 มันใหญ่แค่ไหนกันครับ?

เท่านี้ครับ (เห็นภาพแล้วอึ้งกันไหมครับ?) ชิฟที่แรงกว่า PS5(Play Station 5) ถึง 2 เท่าและโหดกว่า RTX 3090 ถึง 10 เท่า แถมยังสามารถส่งข้อมูลได้เยอะกว่า Intel® Core™ i9-11900KB Processor อยู่ประมาณ 312 เท่าเองครับ หน้าตาเท่านี้เองครับ
BLINK DRIVE TAKE
อย่างที่รู้คือ Chipset แต่ล่ะรุ่นจะมีความสามารถพิเศษแตกต่างออกไปจากสถาปัตยกรรมด้านใน เช่น intel core i9 ก็เน้นเรื่องการประมวลผล, Nvidia RTX 3090 เน้นเรื่องการ raytracing(เดี๋ยวจะอธิบายในกระทู้ถัดไป)และการ render ภาพ, และ Intel Barefoot Tofino 2 เน้นเรื่องการรับส่งข้อมูล
ชิฟที่ผมกล่าวมานั้น ค่ายเทสล่าเอาชนะเกือบหมดแล้วเพราะเค้าออกแบบชิฟให้รับรอง software ที่เค้าอยากจะรันนะครับ
สาเหตุหลักที่เทสล่าหันมาทำชิฟ D1 เป็นของตนเองเพราะบริษัทต่างๆ ที่ผลิตชิฟนั้นผลิตไม่โดนใจเทสล่าเลยซักบริษัทแถมเวลาเทสล่าสั่งซื้อชิฟ (อย่างการ์ดจอ 10,000 ใบ) เค้าก็ไม่ได้จะหันมาทำตามสเปคที่เทสล่าอยากได้เลยครับ ทำให้เทสล่าตัดสินใจมาผลิตเสียเองเลยจะได้ประหยัดเรื่องงบประมาณจัดซื้อและได้สเปคชิฟที่ตัวเองต้องการ
นี่ยังเป็นแค่น้ำจิ้มของ AI Day ฝั่ง Hardware ครับ
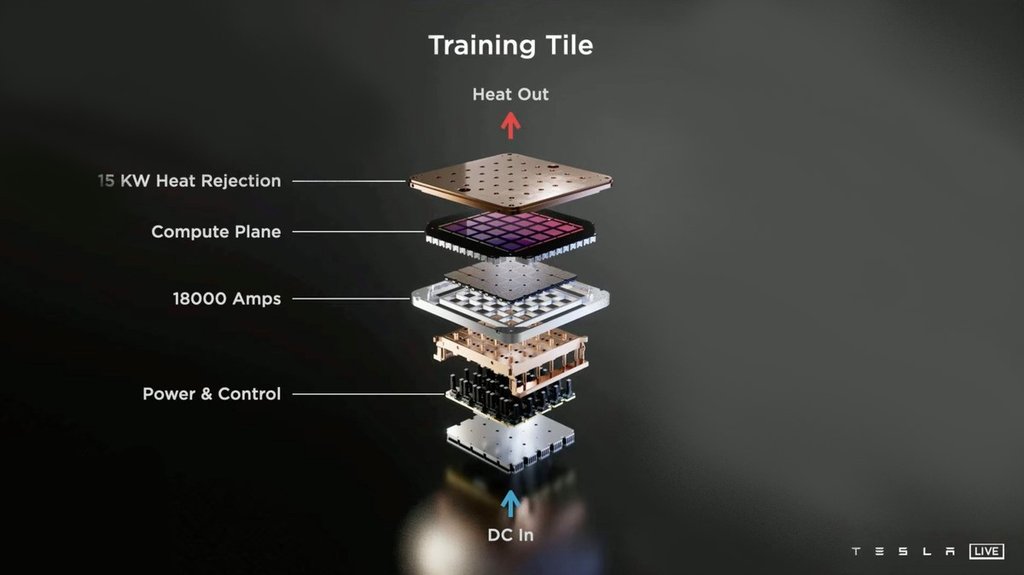
เดี๋ยวผมจะเล่าเรื่อง training tile ในกระทู้ถัดไปนะครับ